Introduction
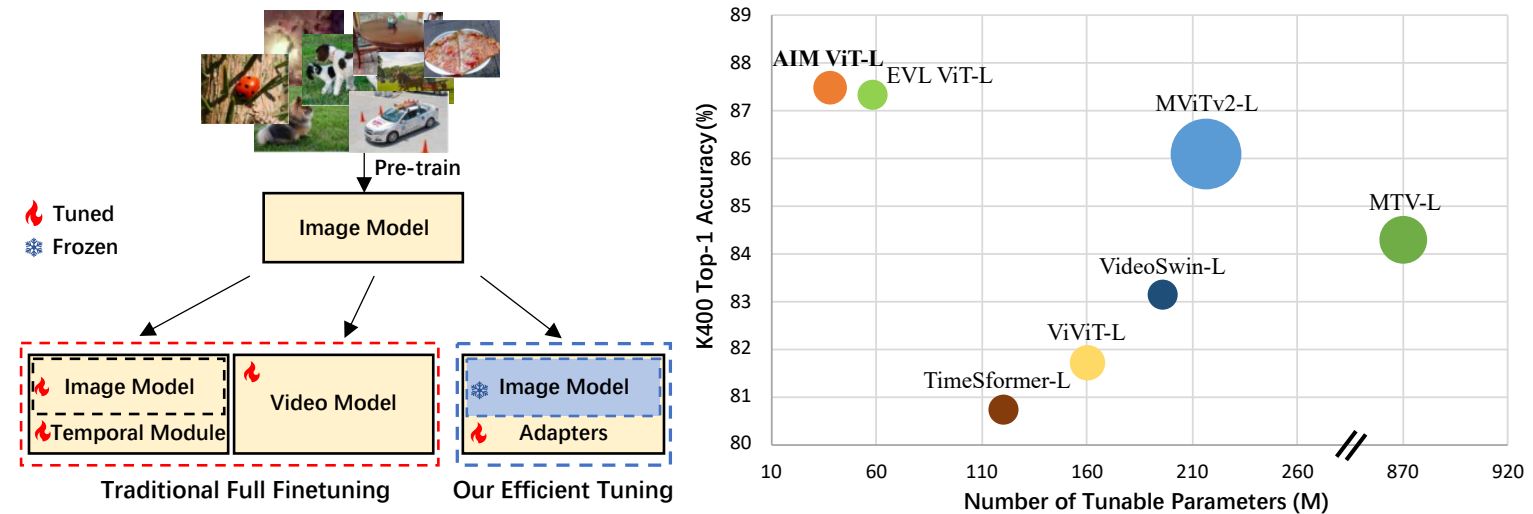
In video understanding, a common practice is bootstrapping from an image pre-trained model and then finetuning on the video data. There are two dominating directions as shown in the left part of the figure above, one is to extend an image model with additional temporal module, the other is to inflate an image model to a video model. However, full finetuning such a video model could be computationally expensive and unnecessary, given that the pre-trained image transformer models have demonstrated exceptional transferability. In this work, we propose a novel method to Adapt pre-trained Image Models (AIM) for efficient video understanding. By freezing the pre-trained image model and adding a few lightweight Adapters, we introduce spatial adaptation, temporal adaptation and joint adaptation to gradually equip an image model with spatiotemporal reasoning capability. We show that our proposed AIM can achieve competitive or even better performance than prior arts with substantially fewer tunable parameters on four video action recognition benchmarks. Thanks to its simplicity, our method is also generally applicable to different image pre-trained models, which has the potential to leverage more powerful image foundation models in the future.
Methodology
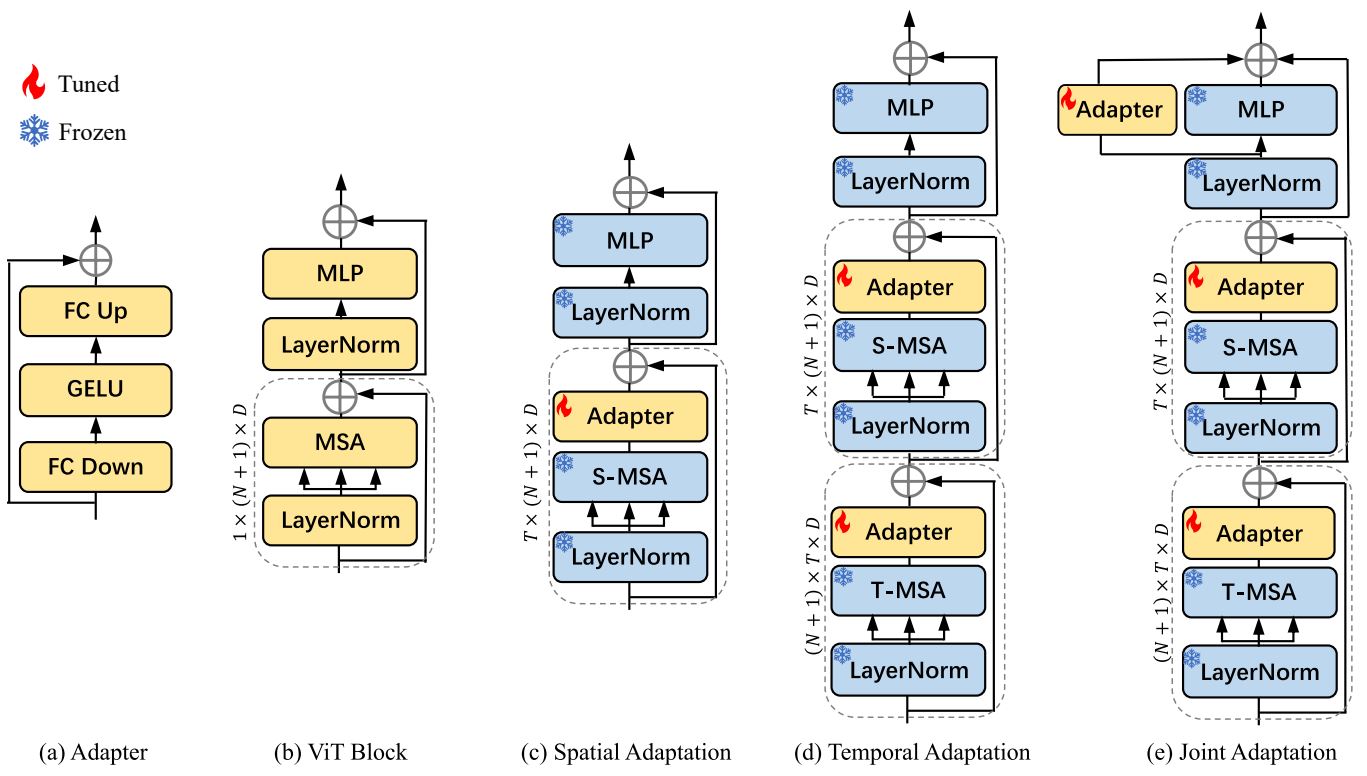
Video understanding requires the model to achieve both good spatial and temporal modeling. We propose Spatial Adaptation for spatial modeling, Temporal Adaptation for
Temporal Modeling, and Joint Adaptation to tune the spatiotemporal representations jointly.
Spatial Adaptation. Since image pre-trained models have been trained on large-scale datasets and demonstrated strong
transferability to downstream tasks, we believe they could achieve good spatial modeling in video
action recognition with minimal finetuning. Motivated by this, we add Adapters after the Spatial Attention layer in the pre-trained image model to tune the pre-trained
representations on video data.
Temporal Adaptation. Spatial Adaptation helps the frozen image model to learn good spatial representations in video data. But the model still lacks the ability
for temporal modeling. Previous works usually introduce new temporal modules to achieve temporal modeling, but this will introduce sizable number of extra model parameters
and these temporal modules requires training from scratch. To address this problem, we present a new strategy: reuse the pre-trained self-attention layer in
the image model to do temporal modeling. As shown in the figure above, we simply reshape the input and use the image pre-trained attention layer to conduct self-attention
on the temporal dimension. Then we add an Adapter after it to tune the extracted features. This simple strategy allows us to achieve good temporal modeling without introducing
new temporal modules.
Joint Adaptation. Spatial and Temporal adaptation are performed sequentially to different input dimensions with their
individual purposes. It would be desirable to jointly tune the representations for spatiotemporal
reasoning. To this end, we further introduce an Adapter in parallel to the MLP layer, which we term
as joint adaptation
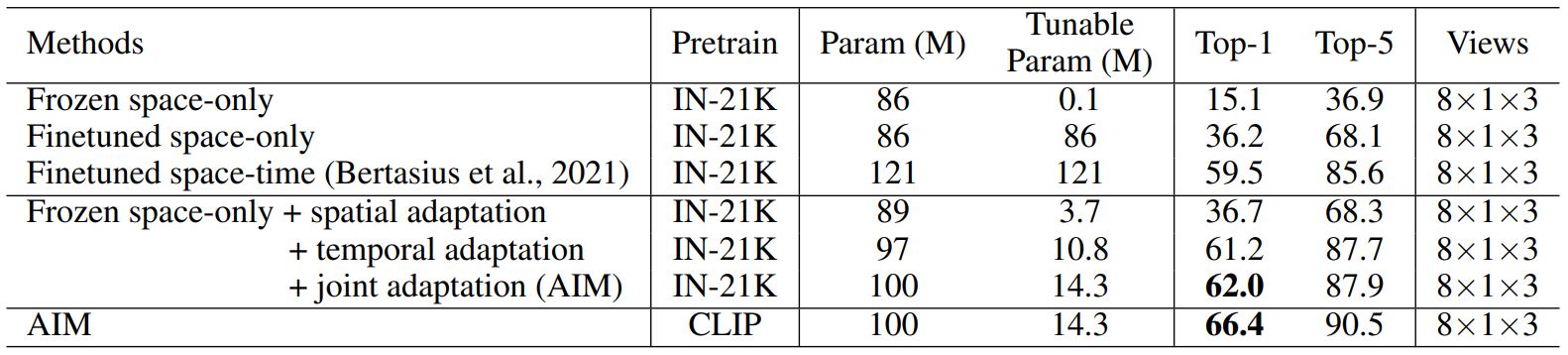
The ablation study to show the effectiveness of each component is shown below
Experimental Results
Though being simple, AIM achieve competitive or even better performance than state-of-the-art full finetuned video models on multiple video benchmarks. The results are shown below.
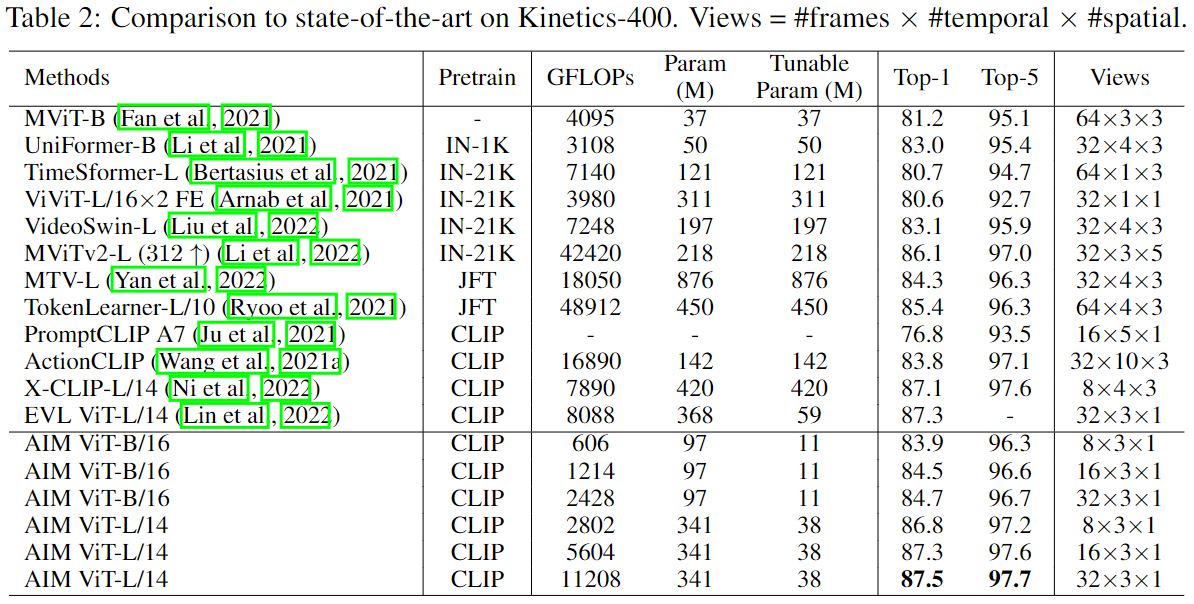
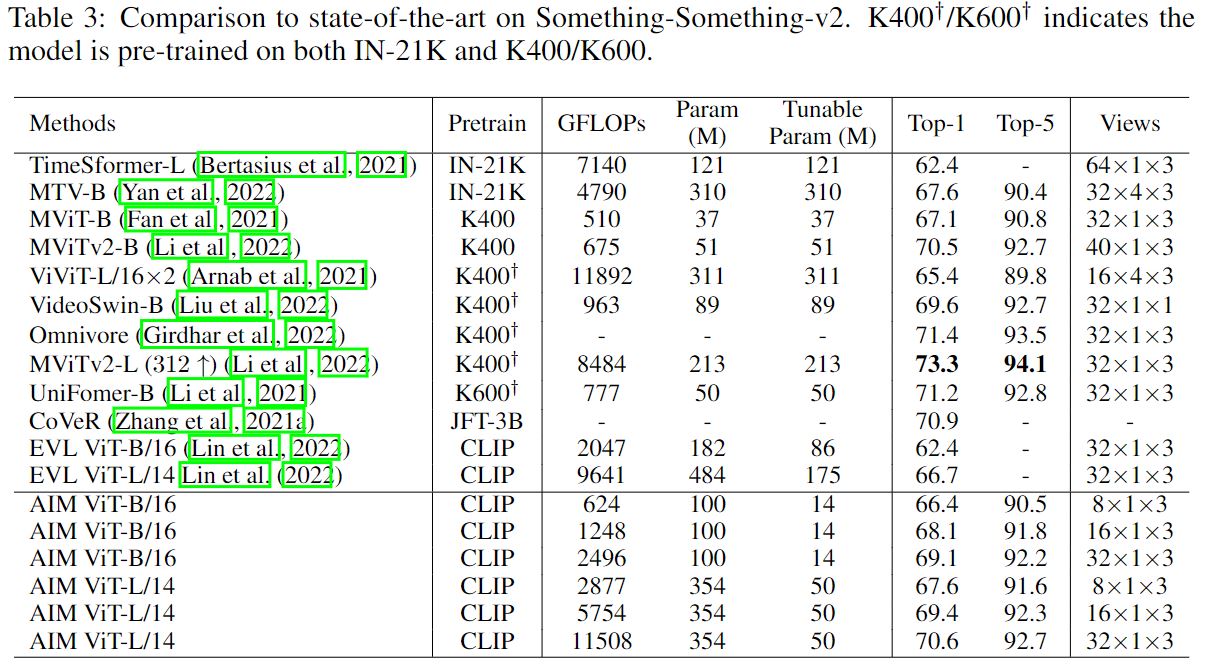
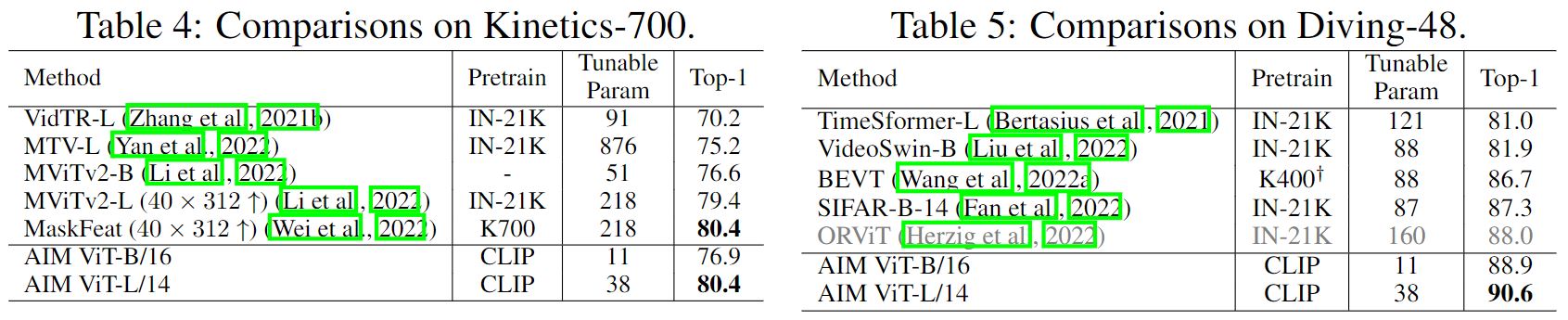
Ablation and Discussion
Thanks to the simplicity, AIM can be easily applied to different network structures. In the table below, we show that AIM can be applied to different pre-trained image data and different image models. AIM achieves comparable or better performance than the full finetuned video models while tuning much less number of parameters and considerably save training memory and time.
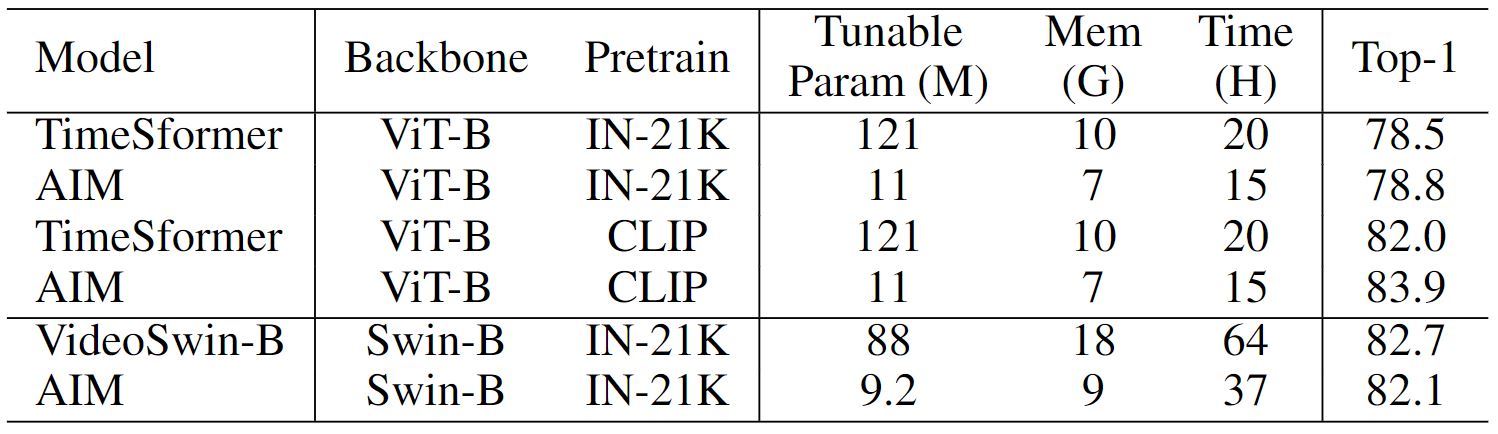
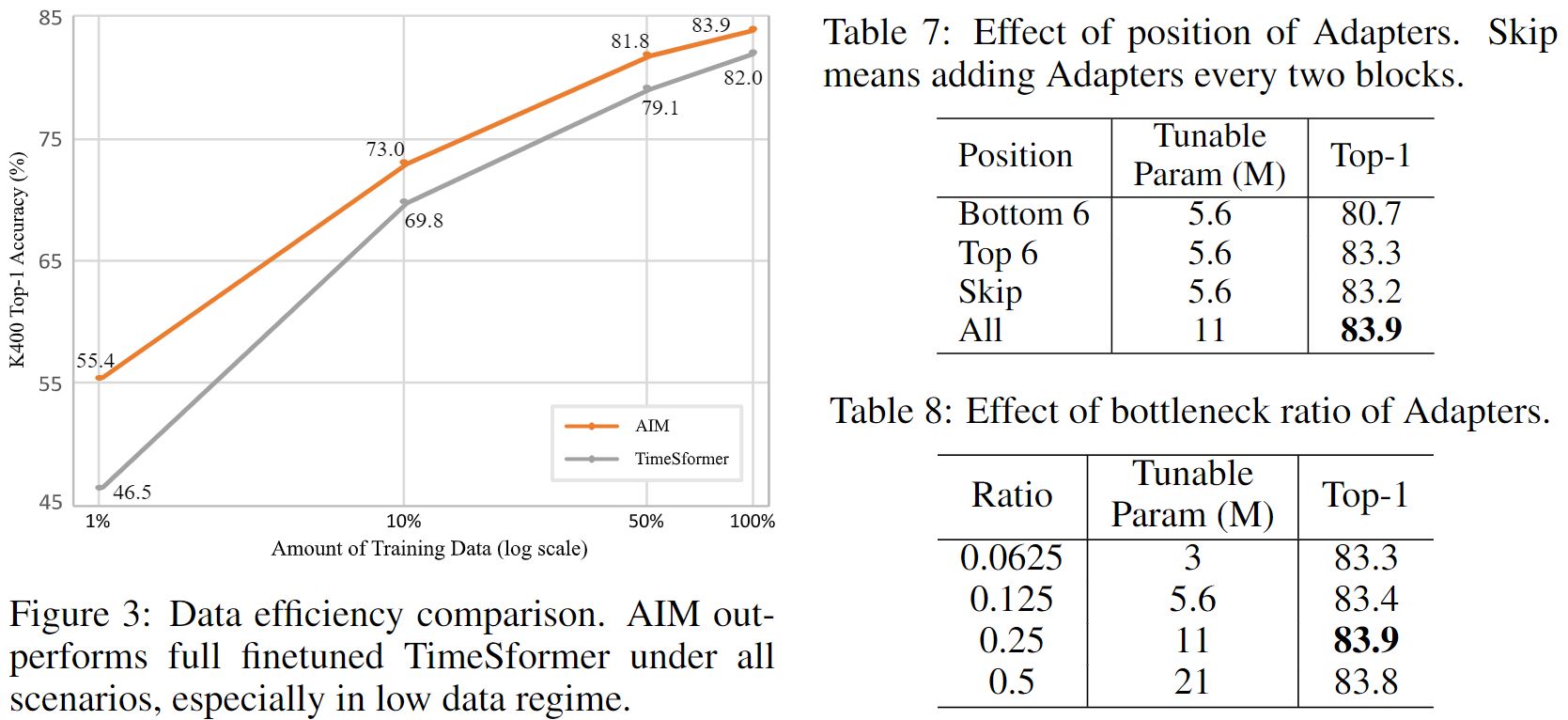
One advantage of our efficient tuning paradigm is that we can keep the well pre-trained image representations intact. In the scenario where downtream data is insufficient, AIM will be less prone to over-fitting problem compared to full finetuning. As shown in the figure below, the advantage of AIM becomes larger when the amount of data becomes less. In the table below, we also show the effect of position of Adapters and the bottoleneck ratio of Adapters.
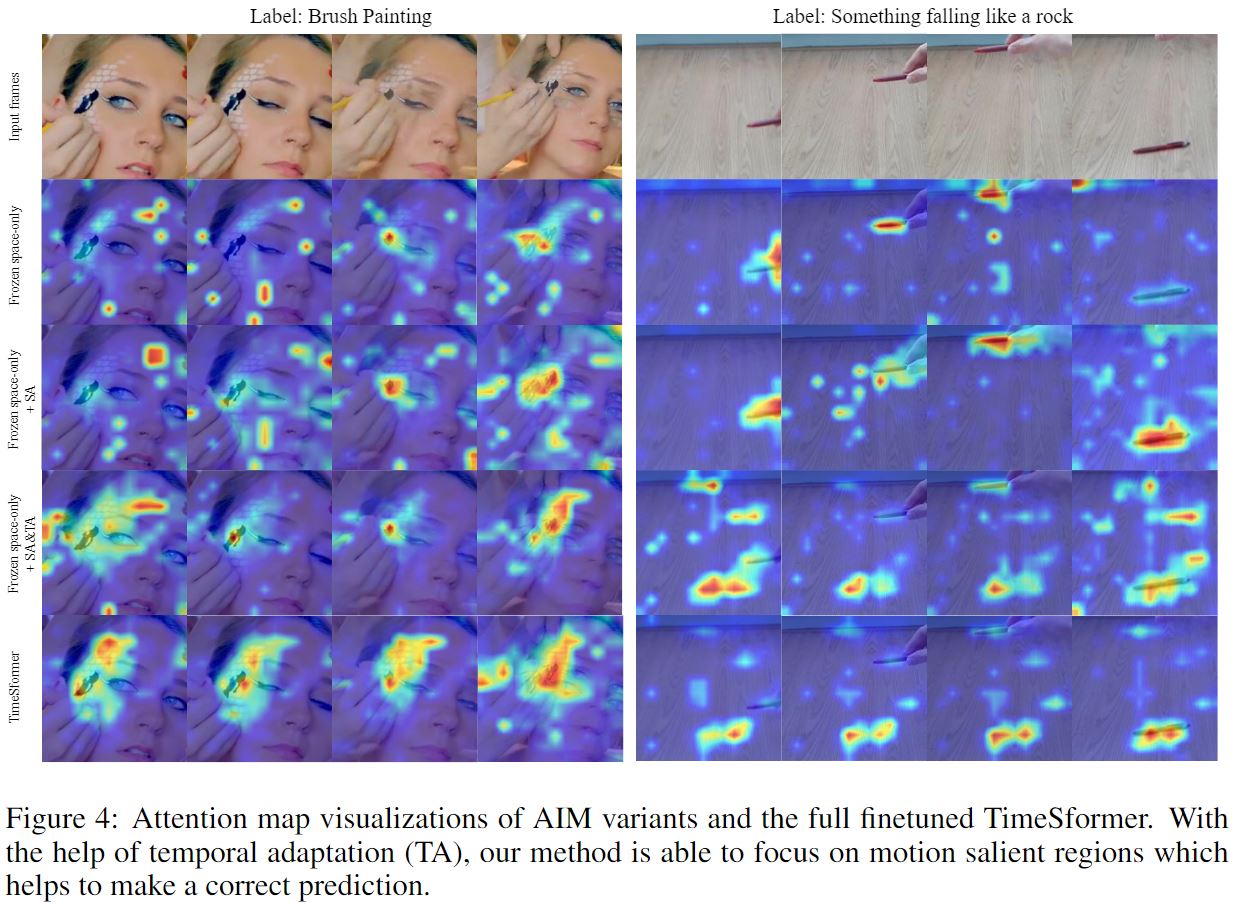
In the figure below, we show the attention map of AIM and other baselines. On the left part, we can see Spatial Adaptation and Temporal Adaptation gradually enhance the attention on the brush painting area. On the right part, we can see that the Temporal Adaptation helps the model to learn the track of the object, which helps the model to make the correct prediction.